本文介绍Bert的基本原理和代码实现。
简介 Bert作为自然语言处理领域最常见的模型,受到广泛的关注。首先我们需要意识到,Bert本身是一个特征提取器,即给定一个文本提取文本串中的相互关联的信息的。这些提取出来的特征再经过简单的处理,就可以支持各种下游任务了。
Bert不是横空出世的,它基于两个非常重要的模型:ELMo和GPT。
如上图所示,ELMo是一个上下文敏感的模型,但是为每个下游的任务分别设置了架构;而GPT则不使用上下文的信息,但是它是一个统一的框架,对不同的下游任务可以微调模型。Bert则是在这两个的基础上,提出了上下文敏感、支持不同下游任务的模型。
接下来,从三个方面介绍Bert,分别是Bert使用的训练数据类型,Bert模型的搭建,以及训练过程。最后介绍一下Bert的下游任务。
模型数据 模型输入 自然语言处理中,有一些任务是输入单个句子,判断该句子的属性,另外一些则是输入一对句子,判断句子之间的关系。Bert为了支持这两种任务,训练的时候使用一对文本进行训练,而训练完使用的时候则可以任意选择。
Bert训练样本的输入如下图所示,是三个部分的加和,即词元嵌入+段嵌入+位置嵌入。次元嵌入表示的是,每一个词元经过Embedding后,它的表示,这个表示是通过学习得到的;段嵌入比较简单,前面说过Bert训练的时候包括两句话,为了表示这两句话,第一句话的段嵌入都为0,第二句话的段嵌入为1;位置嵌入则表示词元在句子中的位置,这里的位置嵌入和Transformer不一样,这里的位置嵌入是通过学习得到的。
Bert的编码器如下,其中输入tokens是一个与词表对应的句子对,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class BERTEncoder (nn.Module): """BERT编码器""" def __init__ (self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000 , key_size=768 , query_size=768 , value_size=768 , **kwargs ): super (BERTEncoder, self).__init__(**kwargs) self.token_embedding = nn.Embedding(vocab_size, num_hiddens) self.segment_embedding = nn.Embedding(2 , num_hiddens) self.blks = nn.Sequential() for i in range (num_layers): self.blks.add_module(f"{i} " , d2l.EncoderBlock( key_size, query_size, value_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, dropout, True )) self.pos_embedding = nn.Parameter(torch.randn(1 , max_len, num_hiddens)) def forward (self, tokens, segments, valid_lens ): X = self.token_embedding(tokens) + self.segment_embedding(segments) X = X + self.pos_embedding.data[:, :X.shape[1 ], :] for blk in self.blks: X = blk(X, valid_lens) return X
举例如下:
1 2 3 4 5 6 7 8 9 vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000 , 768 , 1024 , 4 norm_shape, ffn_num_input, num_layers, dropout = [768 ], 768 , 2 , 0.2 encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout)tokens = torch.randint(0 , vocab_size, (2 , 8 )) tokens = torch.randint(0 , vocab_size, (2 , 8 )) segments = torch.tensor([[0 , 0 , 0 , 0 , 1 , 1 , 1 , 1 ], [0 , 0 , 0 , 1 , 1 , 1 , 1 , 1 ]]) encoded_X = encoder(tokens, segments, None ) encoded_X.shape
数据准备 为了训练Bert,我们需要构建一个数据集合,基本的思路是实现一个DataSet类,再由这个类实现DadaLoader类,以批量的方式,产生文本对、段标识、有效长度、掩码位置、掩码标签、掩码权重、两句话是否连续标签。其中掩码权重的意思是,如果掩码位置是认为填充的数据,那么填充词元的预测将通过乘以0权重在损失中过滤掉。
我们加载一个维基百科的数据集,作为训练文本。
因为我们的模型有两个任务,即预测下一句话,以及预测遮蔽的位置的词元,因此我们需要分别为这两个任务准备数据:
生成下一句预测任务的数据 _get_next_sentence函数生成二分类任务的训练样本, _get_nsp_data_from_paragrap 函数调用_get_next_sentence函数从输入paragraph生成用于下一句预测的训练样本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def _get_next_sentence (sentence, next_sentence, paragraphs ): if random.random() < 0.5 : is_next = True else : next_sentence = random.choice(random.choice(paragraphs)) is_next = False return sentence, next_sentence, is_next def _get_nsp_data_from_paragraph (paragraph, paragraphs, vocab, max_len ): nsp_data_from_paragraph = [] for i in range (len (paragraph) - 1 ): tokens_a, tokens_b, is_next = _get_next_sentence( paragraph[i], paragraph[i + 1 ], paragraphs) if len (tokens_a) + len (tokens_b) + 3 > max_len: continue tokens, segments = d2l.get_tokens_and_segments(tokens_a, tokens_b) nsp_data_from_paragraph.append((tokens, segments, is_next)) return nsp_data_from_paragraph
生成遮蔽语言模型任务的数据 _replace_mlm_tokens函数输入tokens是表示BERT输入序列的词元的列表,candidate_pred_positions是不包括特殊词元的BERT输入序列的词元索引的列表(特殊词元在遮蔽语言模型任务中不被预测),以及num_mlm_preds指示预测的数量(选择15%要预测的随机词元);该函数返回可能替换后的输入词元、发生预测的词元索引和这些预测的标签。
_get_mlm_data_from_token函数将BERT输入序列(tokens)作为输入,并返回输入词元的索引、发生预测的词元索引以及这些预测的标签索引。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 def _replace_mlm_tokens (tokens, candidate_pred_positions, num_mlm_preds, vocab ): mlm_input_tokens = [token for token in tokens] pred_positions_and_labels = [] random.shuffle(candidate_pred_positions) for mlm_pred_position in candidate_pred_positions: if len (pred_positions_and_labels) >= num_mlm_preds: break masked_token = None if random.random() < 0.8 : masked_token = '<mask>' else : if random.random() < 0.5 : masked_token = tokens[mlm_pred_position] else : masked_token = random.choice(vocab.idx_to_token) mlm_input_tokens[mlm_pred_position] = masked_token pred_positions_and_labels.append( (mlm_pred_position, tokens[mlm_pred_position])) return mlm_input_tokens, pred_positions_and_labels def _get_mlm_data_from_tokens (tokens, vocab ): candidate_pred_positions = [] for i, token in enumerate (tokens): if token in ['<cls>' , '<sep>' ]: continue candidate_pred_positions.append(i) num_mlm_preds = max (1 , round (len (tokens) * 0.15 )) mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens( tokens, candidate_pred_positions, num_mlm_preds, vocab) pred_positions_and_labels = sorted (pred_positions_and_labels, key=lambda x: x[0 ]) pred_positions = [v[0 ] for v in pred_positions_and_labels] mlm_pred_labels = [v[1 ] for v in pred_positions_and_labels] return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]
将文本转换为预训练数据集 将特殊的“”词元附加到输入。它的参数examples包含来自两个预训练任务的辅助函数_get_nsp_data_from_paragraph和_get_mlm_data_from_tokens的输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def _pad_bert_inputs (examples, max_len, vocab ): max_num_mlm_preds = round (max_len * 0.15 ) all_token_ids, all_segments, valid_lens, = [], [], [] all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], [] nsp_labels = [] for (token_ids, pred_positions, mlm_pred_label_ids, segments, is_next) in examples: all_token_ids.append(torch.tensor(token_ids + [vocab['<pad>' ]] * ( max_len - len (token_ids)), dtype=torch.long)) all_segments.append(torch.tensor(segments + [0 ] * ( max_len - len (segments)), dtype=torch.long)) valid_lens.append(torch.tensor(len (token_ids), dtype=torch.float32)) all_pred_positions.append(torch.tensor(pred_positions + [0 ] * ( max_num_mlm_preds - len (pred_positions)), dtype=torch.long)) all_mlm_weights.append( torch.tensor([1.0 ] * len (mlm_pred_label_ids) + [0.0 ] * ( max_num_mlm_preds - len (pred_positions)), dtype=torch.float32)) all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0 ] * ( max_num_mlm_preds - len (mlm_pred_label_ids)), dtype=torch.long)) nsp_labels.append(torch.tensor(is_next, dtype=torch.long)) return (all_token_ids, all_segments, valid_lens, all_pred_positions, all_mlm_weights, all_mlm_labels, nsp_labels)
将用于生成两个预训练任务的训练样本的辅助函数和用于填充输入的辅助函数放在一起,我们定义以下_WikiTextDataset类为用于预训练BERT的WikiText-2数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class _WikiTextDataset (gluon.data.Dataset): def __init__ (self, paragraphs, max_len ): paragraphs = [d2l.tokenize( paragraph, token='word' ) for paragraph in paragraphs] sentences = [sentence for paragraph in paragraphs for sentence in paragraph] self.vocab = d2l.Vocab(sentences, min_freq=5 , reserved_tokens=[ '<pad>' , '<mask>' , '<cls>' , '<sep>' ]) examples = [] for paragraph in paragraphs: examples.extend(_get_nsp_data_from_paragraph( paragraph, paragraphs, self.vocab, max_len)) examples = [(_get_mlm_data_from_tokens(tokens, self.vocab) + (segments, is_next)) for tokens, segments, is_next in examples] (self.all_token_ids, self.all_segments, self.valid_lens, self.all_pred_positions, self.all_mlm_weights, self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs( examples, max_len, self.vocab) def __getitem__ (self, idx ): return (self.all_token_ids[idx], self.all_segments[idx], self.valid_lens[idx], self.all_pred_positions[idx], self.all_mlm_weights[idx], self.all_mlm_labels[idx], self.nsp_labels[idx]) def __len__ (self ): return len (self.all_token_ids)
最终,生成dataloader类:
1 2 3 4 5 6 7 8 9 10 def load_data_wiki (batch_size, max_len ): """加载WikiText-2数据集""" num_workers = d2l.get_dataloader_workers() data_dir = d2l.download_extract('wikitext-2' , 'wikitext-2' ) paragraphs = _read_wiki(data_dir) train_set = _WikiTextDataset(paragraphs, max_len) train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True , num_workers=num_workers) return train_iter, train_set.vocab
模型搭建 Bert的损失函数有两个来源:预测一句话中掩码的损失,预测第二句话和第一句话是否连续。
因此我们的Bert模型需要首先分别实现这两个功能。
Masked Language Modeling 我们知道Bert随机选择一句话中15%的词元作为预测的掩蔽词源,下面这个类就是为了预测这个掩蔽位置的词元的,它需要两个输入,即BertEncoder的编码结果,和用于预测的词元位置。这是一个分类问题,它的输出是我们选择掩蔽的位置,对应的单词在此表中的位置,用ont-hot编码。如果已知了标签,就可以就是交叉熵损失函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class MaskLM (nn.Module): """BERT的掩蔽语言模型任务""" def __init__ (self, vocab_size, num_hiddens, num_inputs=768 , **kwargs ): super (MaskLM, self).__init__(**kwargs) self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens), nn.ReLU(), nn.LayerNorm(num_hiddens), nn.Linear(num_hiddens, vocab_size)) def forward (self, X, pred_positions ): num_pred_positions = pred_positions.shape[1 ] pred_positions = pred_positions.reshape(-1 ) batch_size = X.shape[0 ] batch_idx = torch.arange(0 , batch_size) batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions) masked_X = X[batch_idx, pred_positions] masked_X = masked_X.reshape((batch_size, num_pred_positions, -1 )) mlm_Y_hat = self.mlp(masked_X) return mlm_Y_hat
Next Sentence Prediction 除了提取一句话中上下文的信息,Bert还建模了文本对之间的逻辑关系。简单来说就是判断这两句话是否属于上下文,这同样是一个二分类问题。
1 2 3 4 5 6 7 8 9 class NextSentencePred (nn.Module): """BERT的下一句预测任务""" def __init__ (self, num_inputs, **kwargs ): super (NextSentencePred, self).__init__(**kwargs) self.output = nn.Linear(num_inputs, 2 ) def forward (self, X ): return self.output(X)
假设批量大小为b,两个句子加在一起的长度是s,每个词元嵌入的维度是h,词表的大小是v
对输入的一个批量的数据b×s,首先进行encoder编码(包括词嵌入,位置编码和段嵌入)得到大小为b×s×h ;每个句子中选择n个掩码位置,输出预测结果为b ×n×v;拿每个句子的cls位置出来预测两句话是否连续,输出大小为b×2。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class BERTModel (nn.Module): """BERT模型""" def __init__ (self, vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=1000 , key_size=768 , query_size=768 , value_size=768 , hid_in_features=768 , mlm_in_features=768 , nsp_in_features=768 ): super (BERTModel, self).__init__() self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout, max_len=max_len, key_size=key_size, query_size=query_size, value_size=value_size) self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens), nn.Tanh()) self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features) self.nsp = NextSentencePred(nsp_in_features) def forward (self, tokens, segments, valid_lens=None , pred_positions=None ): encoded_X = self.encoder(tokens, segments, valid_lens) if pred_positions is not None : mlm_Y_hat = self.mlm(encoded_X, pred_positions) else : mlm_Y_hat = None nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0 , :])) return encoded_X, mlm_Y_hat, nsp_Y_hat
模型训练 训练模型的损失函数是遮蔽语言模型的损失+下一句预测的损失。其中的d2l.Animator是一个画图的类,不影响训练过程。我们在前面构建的dataloader中批量的生成数据,每个批量的数据包括:
tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y
对应输入的词元,段辨识,有效长度,掩码的位置,掩码的权重,掩码的标签,下一句标签
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 def _get_batch_loss_bert (net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y ): _, mlm_Y_hat, nsp_Y_hat = net(tokens_X, segments_X, valid_lens_x.reshape(-1 ), pred_positions_X) mlm_l = loss(mlm_Y_hat.reshape(-1 , vocab_size), mlm_Y.reshape(-1 )) *\ mlm_weights_X.reshape(-1 , 1 ) mlm_l = mlm_l.sum () / (mlm_weights_X.sum () + 1e-8 ) nsp_l = loss(nsp_Y_hat, nsp_y) l = mlm_l + nsp_l return mlm_l, nsp_l, l def train_bert (train_iter, net, loss, vocab_size, devices, num_steps ): net = nn.DataParallel(net, device_ids=devices).to(devices[0 ]) trainer = torch.optim.Adam(net.parameters(), lr=0.01 ) step, timer = 0 , d2l.Timer() animator = d2l.Animator(xlabel='step' , ylabel='loss' , xlim=[1 , num_steps], legend=['mlm' , 'nsp' ]) metric = d2l.Accumulator(4 ) num_steps_reached = False while step < num_steps and not num_steps_reached: for tokens_X, segments_X, valid_lens_x, pred_positions_X,\ mlm_weights_X, mlm_Y, nsp_y in train_iter: tokens_X = tokens_X.to(devices[0 ]) segments_X = segments_X.to(devices[0 ]) valid_lens_x = valid_lens_x.to(devices[0 ]) pred_positions_X = pred_positions_X.to(devices[0 ]) mlm_weights_X = mlm_weights_X.to(devices[0 ]) mlm_Y, nsp_y = mlm_Y.to(devices[0 ]), nsp_y.to(devices[0 ]) trainer.zero_grad() timer.start() mlm_l, nsp_l, l = _get_batch_loss_bert( net, loss, vocab_size, tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X, mlm_Y, nsp_y) l.backward() trainer.step() metric.add(mlm_l, nsp_l, tokens_X.shape[0 ], 1 ) timer.stop() animator.add(step + 1 , (metric[0 ] / metric[3 ], metric[1 ] / metric[3 ])) step += 1 if step == num_steps: num_steps_reached = True break print (f'MLM loss {metric[0 ] / metric[3 ]:.3 f} , ' f'NSP loss {metric[1 ] / metric[3 ]:.3 f} ' ) print (f'{metric[2 ] / timer.sum ():.1 f} sentence pairs/sec on ' f'{str (devices)} ' )
下游任务
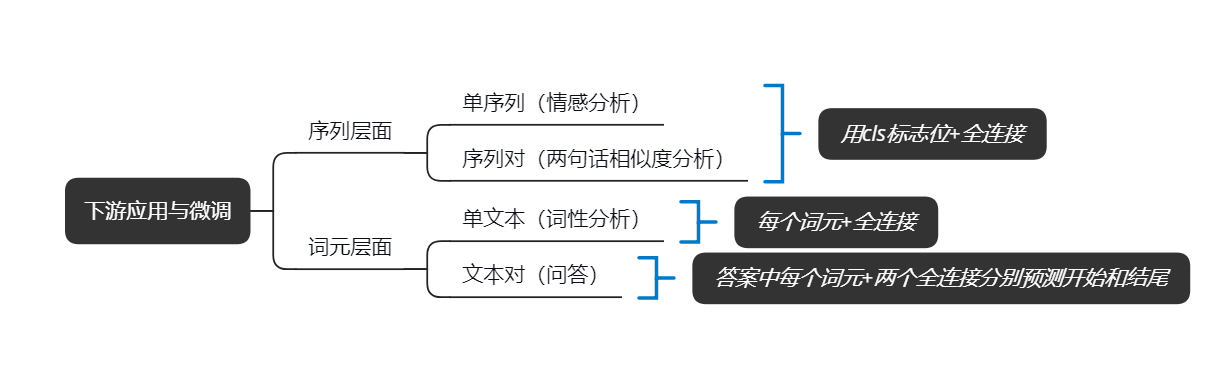
Bert的下游任务可以有两个基本的分类,即层序层面和词元层面。
如下表所示,序列层面的应用又可以分为是单序列任务,例如句子的情感分析,或者是多序列任务(两句话的相似度分析);在序列层面的任务,都是只需要用句子的第一个标志位加一个mlp网络就可以了。
在词元层面,也可以分为单本文和文本对,对于单文本,例如词性分析或者翻译,对于每一个词元共享同一个全连接网络,依次输出结果;对于文本对,例如问答,我们用两个mlp网络分别预测每个词元的开始和结尾。