本文介绍python中的进程与线程的概念,以及如何编写多进程与多线程的代码。
进程与线程
进程:对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
线程:在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread),比如Word,它可以同时进行打字、拼写检查、打印等事情。
前面编写的所有的Python程序,都是执行单任务的进程,也就是只有一个线程。
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
多进程和多线程的程序涉及到同步、数据共享的问题,编写起来更复杂。
多进程
在代码中的多线程和多进程,具体说来是同时执行多个函数。因此多线程操作,基本都是指涉及一个可以并行的函数,并封装到给定的类中,由给定的类的方法控制并行处理、等待等过程。
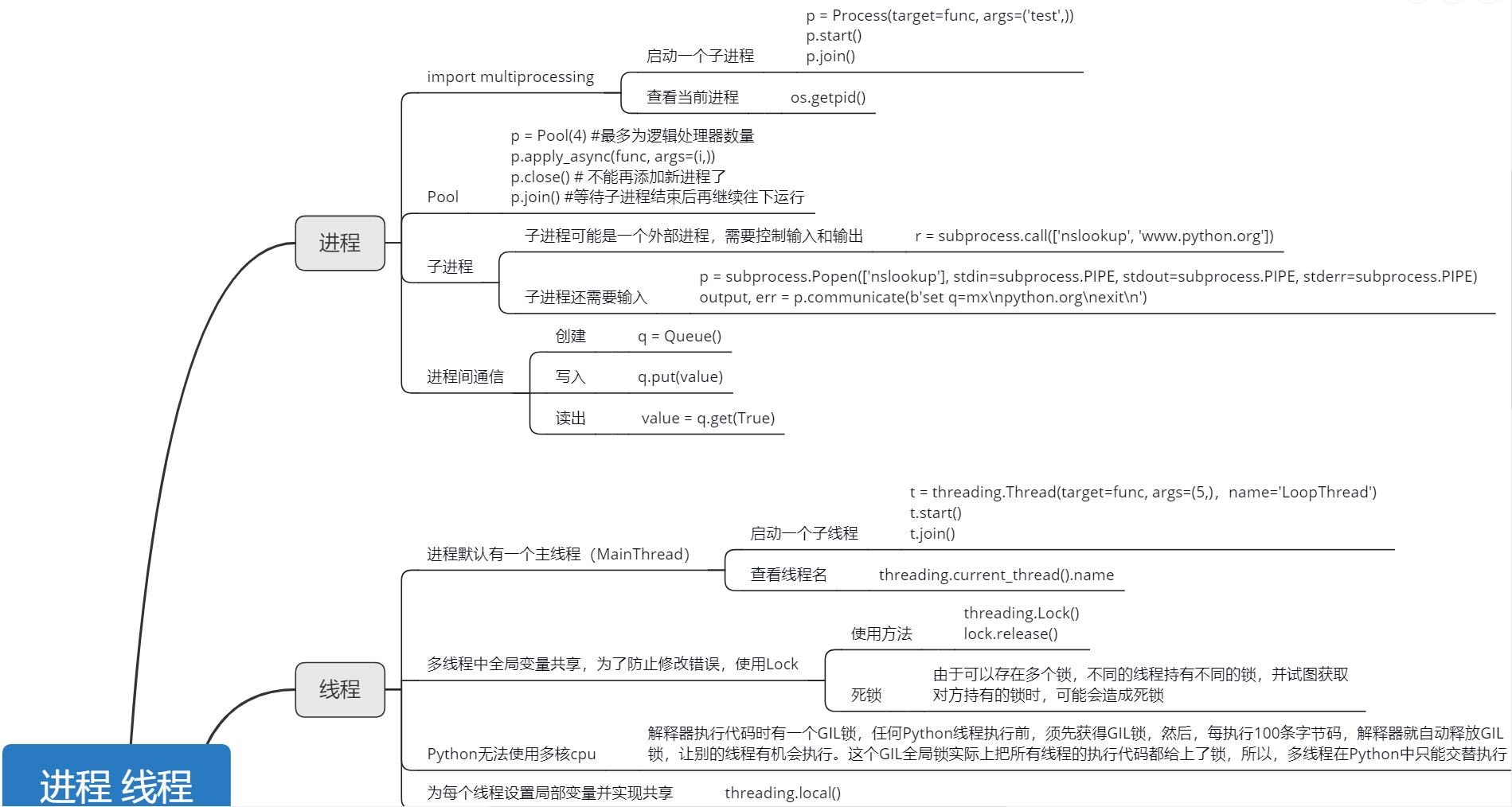
multiprocessing
python提供了一个跨平台的多进程模块multiprocessing,用于实现多进程编码。该模块有一个Process类,用来代表一个进程对象,
1 | from multiprocessing import Process |
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动,join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步。
Pool
如果要启动大量的子进程,可以用进程池的方式批量创建子进程:
1 | from multiprocessing import Pool |
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。
请注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool的默认大小在我的电脑上是4,因此,最多同时执行4个进程。这是Pool有意设计的限制,并不是操作系统的限制。
由于Pool的默认大小是CPU的核数。
子进程
很多时候,子进程并不是自身,而是一个外部进程。我们创建了子进程后,还需要控制子进程的输入和输出。
subprocess模块可以让我们非常方便地启动一个子进程,然后控制其输入和输出。
下面的例子演示了如何在Python代码中运行命令nslookup www.python.org,这和命令行直接运行的效果是一样的:
1 | import subprocess |
如果子进程还需要输入,则可以通过communicate()方法输入:
1 | import subprocess |
进程间通信
Process之间肯定是需要通信的,操作系统提供了很多机制来实现进程间的通信。Python的multiprocessing模块包装了底层的机制,提供了Queue、Pipes等多种方式来交换数据。
我们以Queue为例,在父进程中创建两个子进程,一个往Queue里写数据,一个从Queue里读数据:
1 | from multiprocessing import Process, Queue |
除了使用multiprocessing模型进行多进程编程外,在Unix和Linux或者mac系统下,也可以使用fock()命令实现多进程。
多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:
1 | import time, threading |
由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用LoopThread命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1,Thread-2……
Lock
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
1 | import time, threading |
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
原因是因为高级语言的一条语句在CPU执行时是若干条语句,即使一个简单的计算:
也分两步:
计算
balance + n,存入临时变量中;将临时变量的值赋给
balance。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15初始值 balance = 0
t1: x1 = balance + 5 # x1 = 0 + 5 = 5
t2: x2 = balance + 8 # x2 = 0 + 8 = 8
t2: balance = x2 # balance = 8
t1: balance = x1 # balance = 5
t1: x1 = balance - 5 # x1 = 5 - 5 = 0
t1: balance = x1 # balance = 0
t2: x2 = balance - 8 # x2 = 0 - 8 = -8
t2: balance = x2 # balance = -8
结果 balance = -8
究其原因,是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改balance的时候,别的线程一定不能改。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:-
1 | balance = 0 |
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
死锁
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
死锁的例子:
1 | from threading import Lock, Thread, current_thread |
可以使用上下文管理器来避免死锁问题。我们要做的就是在lock的外面包装一层,使得我们在获取和释放锁的时候可以根据我们的需要,对锁进行排序,按照升序的顺序进行持有。
多线程之间的通信
多进程之间的通信可以分为两种主要的方式,第一是共享变量,单来说就是定义一个全局变量来实现。这里需要注意共享变量的更新可能会出现问题,此时需要加锁。
线程之间的通信最安全的方式就是queue库中的队列。多个线程之间通过put()和get()操作来向队列中添加或者删除元素。这个操作和多进程里的通信方式类似。Queue对象已经包括了必要的锁,因此它是多线程安全的。
多核CPU
Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
不过,也不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
多线程编程,模型复杂,容易发生冲突,必须用锁加以隔离,同时,又要小心死锁的发生。
Python解释器由于设计时有GIL全局锁,导致了多线程无法利用多核。多线程的并发在Python中就是一个美丽的梦。
ThreadLocal
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
但是局部变量也有问题,就是在函数调用的时候,传递起来很麻烦:
1 | def process_student(name): |
每个函数一层一层调用都这么传参数那还得了?用全局变量?也不行,因为每个线程处理不同的Student对象,不能共享。
如果用一个全局dict存放所有的Student对象,然后以thread自身作为key获得线程对应的Student对象如何?
1 | global_dict = {} |
这种方式理论上是可行的,它最大的优点是消除了std对象在每层函数中的传递问题,但是,每个函数获取std的代码有点丑。
有没有更简单的方式?
ThreadLocal应运而生,不用查找dict,ThreadLocal帮你自动做这件事:
1 | import threading |
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
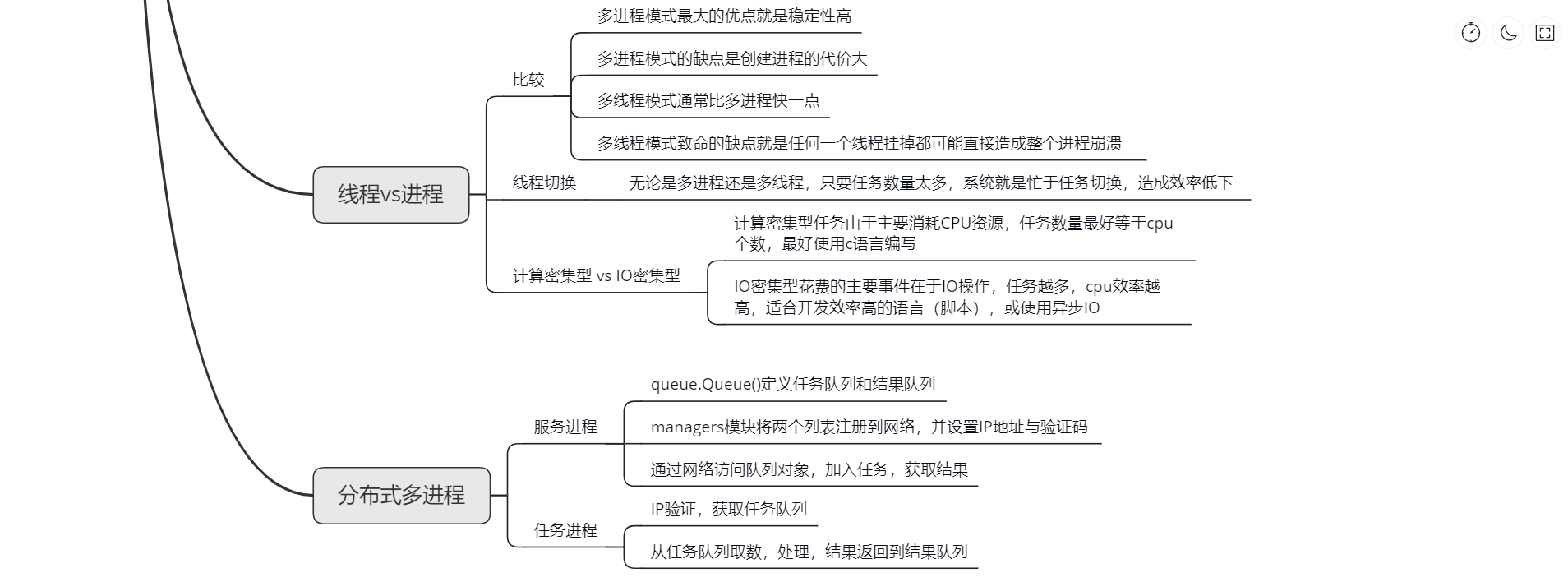
进程 vs 线程
要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务。
| 优点 | 缺点 | |
|---|---|---|
| 多进程 | 稳定性高(一个子进程崩溃了,不会影响主进程和其他子进程) | 创建进程的代价大 |
| 多线程 | 比多进程快一点 | 任何一个线程挂掉都可能直接造成整个进程崩溃(所有线程共享进程的内存) |
那么是否采用多线程or多进程呢?这个具体得看情况分析:
首先需要看效率问题,无论是多进程还是多线程,只要数量一多,效率肯定上不去。因为线程切换是有代价的,包括保存现场、准备新环境等。
其次看任务类型,我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。对于计算密集型任务,最好用C语言编写。
IO密集型任务任务越多,CPU效率越高,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。或者使用异步IO编程。
分布式进程
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
举个例子:如果我们已经有一个通过Queue通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
原有的Queue可以继续使用,但是,通过managers模块把Queue通过网络暴露出去,就可以让其他机器的进程访问Queue了。
我们先看服务进程,服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
1 | import queue |
请注意,当我们在一台机器上写多进程程序时,创建的Queue可以直接拿来用,但是,在分布式多进程环境下,添加任务到Queue不可以直接对原始的task_queue进行操作,那样就绕过了QueueManager的封装,必须通过manager.get_task_queue()获得的Queue接口添加。
然后,在另一台机器上启动任务进程(本机上启动也可以):
1 | # task_worker.py |
任务进程要通过网络连接到服务进程,所以要指定服务进程的IP。
1 | ┌─────────────────────────────────────────┐ ┌──────────────────────────────────────┐ |
Python的分布式进程接口简单,封装良好,适合需要把繁重任务分布到多台机器的环境下。
注意Queue的作用是用来传递任务和接收结果,每个任务的描述数据量要尽量小。比如发送一个处理日志文件的任务,就不要发送几百兆的日志文件本身,而是发送日志文件存放的完整路径,由Worker进程再去共享的磁盘上读取文件。