本文介绍深度学习训练中的分布式训练技术。
分布式训练
分布式训练主要分为两种:数据并行与模型并行。
数据并行
数据并行是两种分布式训练方法中较易实现的一个,对于大多数用例来说已经足够了。
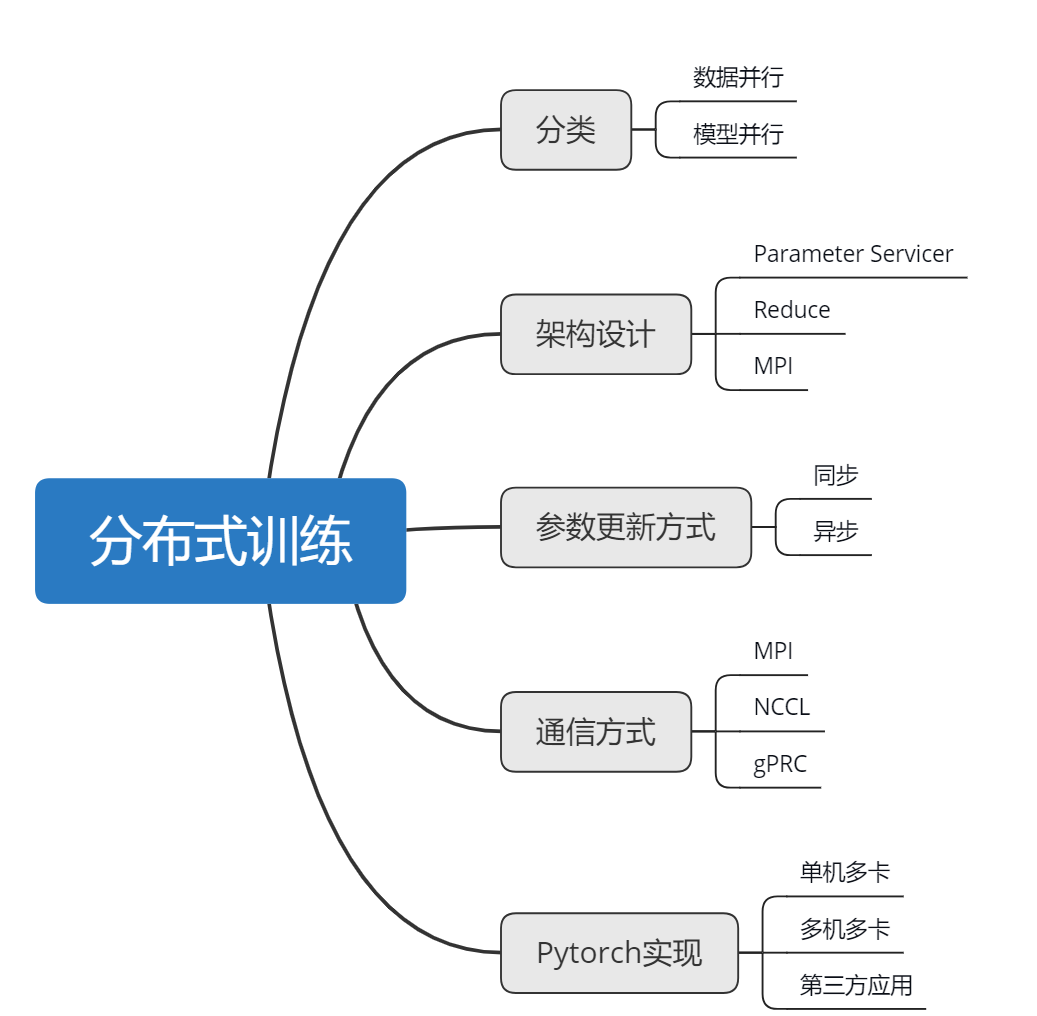
在此方法中,数据划分到计算群集中的分区内,其中分区数等于可用节点的总数。 将在这些工作器节点的每一个中复制模型,每个工作器都操作和处理自己的数据子集。 请记住,每个节点都必须有能力支持正在进行训练的模型,也就是说,模型需要拟合每个节点。 下图直观地阐释了此方法。
每个节点独立计算其训练样本的预测结果与标记输出之间的误差。 每个节点又会基于该误差更新其模型,且必须将其所有更改传达给其他节点,以便其相应更新其自己的模型。 这意味着,工作器节点需要在批处理计算结束时同步模型参数或梯度,以确保其训练的是一致的模型。
模型并行
与数据并行不同,分布式训练中的模型并行是指将整个神经网络模型拆解分布到不同的 GPU 中,不同的 GPU 负责计算网络模型中的不同部分。这通常是在网络模型很大很大、单个 GPU 的显存已经完全装不下整体网络的情况下才会采用。由于深度学习的模型通常包含很多层,层与层之间的运行有先后训练,前向传播和反向梯度计算的时候,前面的层和后面的层都会彼此依赖作为输入输出,因此这种串行的逻辑对加速造成了一定的限制。但是相比起来,我们也算可以通过模型并行的方式把一个超大模型训练起来,不然对于一个单 GPU 的话,超大模型是完全没办法 work 的。因此,对比起来,模型并行由于各个 GPU 只加载了模型的一部分网络结构,存在一定的依赖关系,造成了规模的伸缩性比较差,不能随意的增减 GPU 的数量,因此在实际中运用的并不多。而数据并行的方式,由于各个 GPU 相互独立,方便 GPU 的扩缩容,同时加速效果好,因此在实际中运用较多,但是在某些时候,我们也可以同时结合数据并行和模型并行两种方式。
架构设计
基于参数服务器(Parameter Server)
PS由两部分组成:服务器(server/master)和节点(client/worker)。
- Parameter server 负责整合梯度,更新参数
- woker负责计算,训练网络
有一组机器只用来存储参数和梯度,其他所有的 Worker 与 PS 服务器 通信,把自己的梯度上传(Push)到 PS,PS 把所有 Worker 的梯度收集 计算(通常是求均值),然后各 Worker 再从 PS 拉回(Pull)更新后的 参数/梯度并应用到自己的参数上。这样相比于单机的训练过程,梯度的产生是在多个worker上,而参数的更新是在server上完成。在分布式训练中iteration前多出了pull操作,用以从server读取等待更新的参数,完成计算后需要push操作将产生的梯度返回给server。
单机训练不用考虑这些问题,但在分布式训练中梯度不是存储在一块GPU上的,梯度的收集与参数的更新涉及到一些问题:在每个iteration开始之前,每个计算节点是否能够获得当前的模型参数 ;在每个iteration的计算结束之后,我们能否同样地把所有节点上产生的梯度都收集起来并更新当前参数。
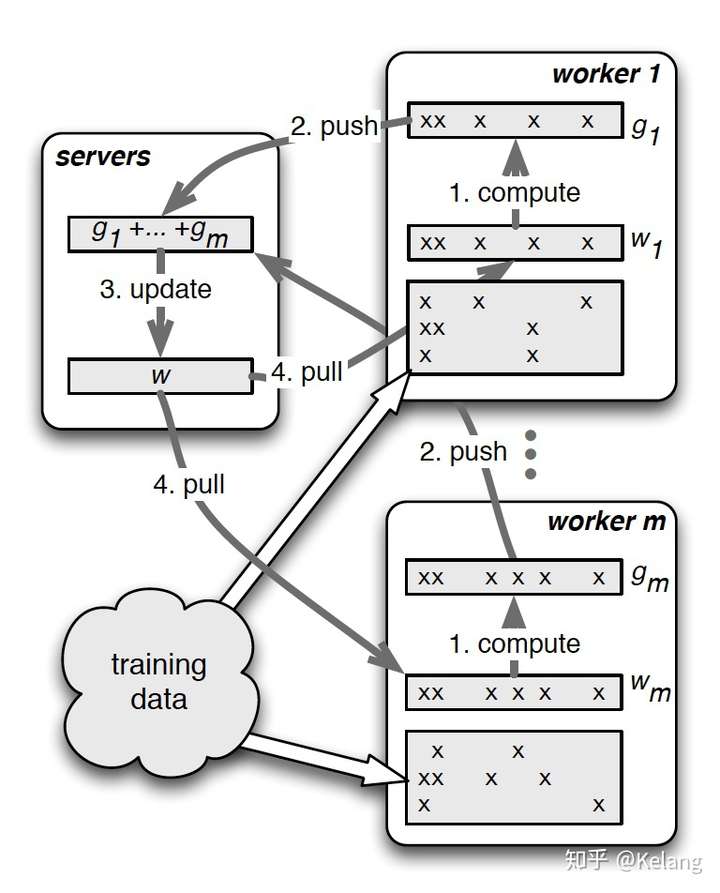
从上图可以很清楚的看到PS的流程,共分为4步。
Task Scheduler:
- 加载数据,并将数据分发给不同的workers
Workers:
计算梯度(1. compute)
加载训练数据
从servers拉取最新的参数(4. Pull)
将梯度push到servers(2.Push)
- 从servers拉取最新的参数(4. Pull)
Servers:
聚合梯度
更新参数(3. Update)
基于规约(Reduce)模式
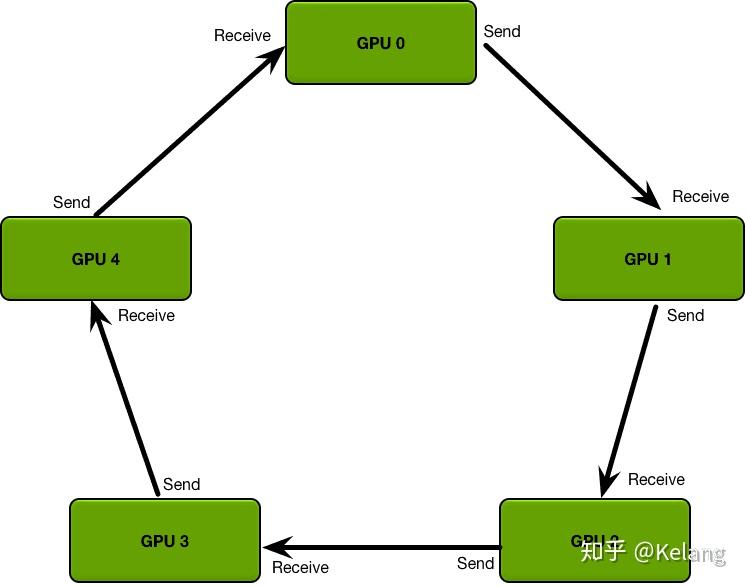
Ring-AllReduce算法的通信成本是恒定的,与系统中gpu的数量无关,完全由系统中gpu之间最慢的连接决定;事实上,如果只考虑带宽作为通信成本的一个因素(并忽略延迟),那么Ring-AllReduce是一种最优通信算法(当模型很大,并且需要发送大量数据的次数很少时,这是一个很好的通信成本估算。)环中的gpu都被安排在一个逻辑环中。每个GPU应该有一个左邻和一个右邻;它只会向它的右邻居发送数据,并从它的左邻居接收数据。
该算法分两个步骤进行:首先是scatter-reduce,然后是allgather。在scatter-reduce步骤中,GPU将交换数据,使每个GPU可得到最终结果的一个块。在allgather步骤中,gpu将交换这些块,以便所有gpu得到完整的最终结果。
基于MPI的方式(互联网中使用的比较少)
「消息传递接口」(Message Passing Interface, MPI) 指程序通过在进程间传递消息(消息可以理解成带有一些信息和数据的 一个数据结构)来完成某些任务。举例来说,主进程(master process)可以通过对从进程(slave process)发送一个描述工作的消息来把这个工作分配给它。另一个例 子就是一个并发的排序程序可以在当前进程中对当前进程可⻅的(我们称作本地的,locally)数据进行排序,然后把排好序的数据发送的邻居 进程上面来进行合并的操作。几乎所有的并行程序可以使用消息传递模 型来描述。 MPI 是一个接口的定义而已,需要程序员去根据不同的架构去实现 这个接口。
同步与异步更新
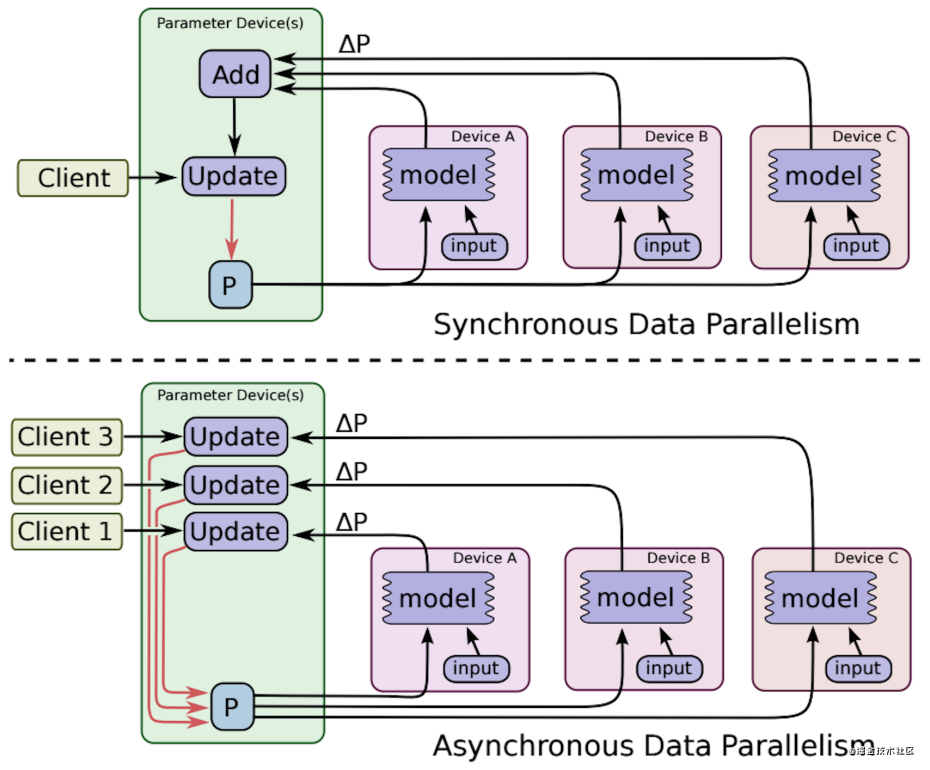
同步(Sync)
当所有的 Worker 完成计算后,才开始进行下一轮迭代。所有 GPU 在同 一时间点与参数服务器交换、融合梯度。 但是传统的同步更新方法(各个 gpu 卡算好梯度,求和算平均的方 式),在融合梯度时,会产生巨大的通信数据量,这种通信压力往往在模型参数量很大时,显得很明显。因此我们需要找到一种方法,来解决 同步更新的网络瓶颈问题。其中最具代表性的一种方法就是:ring-allreduce。
异步(Async)
每个 Worker 完成计算后就尝试更新,能跟其他多少个 Worker之间没有沟通。这种机制避免了木桶效应,但是其过程非常不可控,有可能出现正确性问题。所有 GPU 各自独立与参数服务器通信,交换、融合梯度。
异步更新由于不用等待其他 GPU 节点,因此总体训练速度会快一些,但是会有一个严重的梯度失效的问题。即在异步的情况下,每一个节点完成训练之后,都会马上去更新,这会造成其他节点现在的模型参数和这一轮训练前采用的模型参数可能不一致,从而导致此时的梯度过期。因此,异步更新虽然快,但是由于梯度失效问题,模型往往会陷入到次优解中。
混合 (Mix):
混合模式结合上面两种方式,各个 Worker 都会等待其他 Worker 的完成,但不是永远等待。这里有一个”超时“的机制。这个超时机制可以是超过某个时间,也可以是到达某个最小副本数。如果”超时“了,等待的 Worker 就只用当前获取到的梯度来更新并继续下一个迭代,避免无意义 的等待。而没来得及完成计算的 Worker,其梯度则被标记为”stale“而抛弃或另作处理。
通信方式
MPI
在程序中,不同的进程需要相互的数据交换,特别是在科学计算中,需要大规模的计算与数据交换,集群可以很好解决单节点计算力不足的问题,但在集群中大规模的数据交换是很耗费时间的,因此需要一种在多节点的情况下能快速进行数据交流的标准,这就是MPI。MPI是一组用于多节点数据通信的标准,而非一种语言或者接口。具体的使用方法需要依赖它的具体实现(mpich or openmpi等)。
但其不适合互联网情况下使用:一是MPI的容错性很差;二是MPI的通信是All2All,就是说每台机器都要跟其他所有机器进行通信,通信的复杂度是N2,当机器数大量增加时其通信成本将不可接受。
NCCL
NVIDIA集体通信库(NCCL)实现了针对NVIDIA GPU性能优化的多GPU和多节点集体通信原语。NCCL提供了诸如all-gather, all-reduce, broadcast, reduce, reduce-scatter等动作,这些例程经过优化,可通过PCIe和NVLink高速互连实现高带宽和低延迟。单机多卡默认NCCL方式。
gRPC
在本地调用了一个函数,或者对象的方法,实际上是调用了远程机器上的函数,或者远程对象的方法,但是这个通信过程对于程序员来说是透明的,即达到了一种位置上的透明性。RPC是一种技术思想而非一种规范。协议只规定了 Client 与 Server 之间的点对点调用流程,包括 stub、通信协议、RPC 消息解析等部分,在实际应用中,还需要考虑服务的高可用、负载均衡等问题。
基于Pytorch的分布式训练方法
在 Pytorch 中为我们提供了两种多 GPU 的分布式训练方案:torch.nn.DataParallel(DP)和 torch.nn.parallel.Distributed Data Parallel(DDP)。
Data Parallel
DP 模式使用起来非常容易,只需要对单 GPU 的代码修改其中一行就可以运行了,由于 DP 模式采用的是 PS 架构,存在负载不均衡问题,主卡往往会成为训练的瓶颈,因此训练速度会比 DDP 模式慢一些。而且 DP 只支持单机多卡的方式,一般一台机器只能安装最多 8 张卡,当我们要训练特别大型的任务时,8 卡就会显得特别吃紧,因此会有一定的限制。
1 | # use DataParallel |
Distributed Data Parallel
与 DP 模式不同,DDP 模式本身是为多机多卡设计的,当然在单机多卡的情况下也可以使用。DDP 采用的是 all-reduce 架构,基本解决了 PS 架构中通信成本与 GPU 的数量线性相关的问题。虽然在单机多卡情况下,可以使用 DP 模式,但是使用 DDP 通常会比 DP 模式快一些,因此 DDP 模式也是官方推荐大家使用的方式。改造现有的代码使用 DDP 也非常方便,通过下面几个步骤就可以轻松搞定。
1 | # 1. init backend nccl |
Horovod
除了 Pytorch 原生提供的 DP 和 DDP 方式以外,也有很多优秀的由第三方提供的分布式训练工具,其中 Horovod 就是比较常用的一款。Horovod 是 Uber 开源的跨平台分布式训练框架,从名字可以看出来,Horovod 采用 all-reduce 架构来提高分布式设备的通信效率。同时,Horovod 不仅支持 Pytorch,也支持 TensorFlow 等其他深度学习框架。训练中如果想使用 Horovod 的话,其实对代码的改动也比较少,如下所示。
1 | import horovod.torch as hvd |