本文以Llama2模型为例介绍大语言模型的原理、微调,以及国内优秀的大语言模型。
1. GPT
GPT相关的资料:
- introduce the pre-training + fine-tuning methos to NLP
- Pre-training
- Transformer decoder
- Fine-tuning (linear+softmax layer)
- Textual entailment
- Similarity
- Question Answering
- Commonsense Reasoning
- large and diverse dataset
- article or fiction books
- Common Crawl (mostly unintelligible)
- filter this dataset using Reddit to ensure the used document received at least 3 karma
- WebText
- Zero-shot or few-shot
- scaling up language models
- in-context learning
- Zero-shot
- One-shot
- Few-shot
- align large language with human
- fine-tuning with human feedback
- sorted dataset using reinforcement learning
- cost function is designed for predict next word in a sentence, cause the misalign between human need with model
- three steps
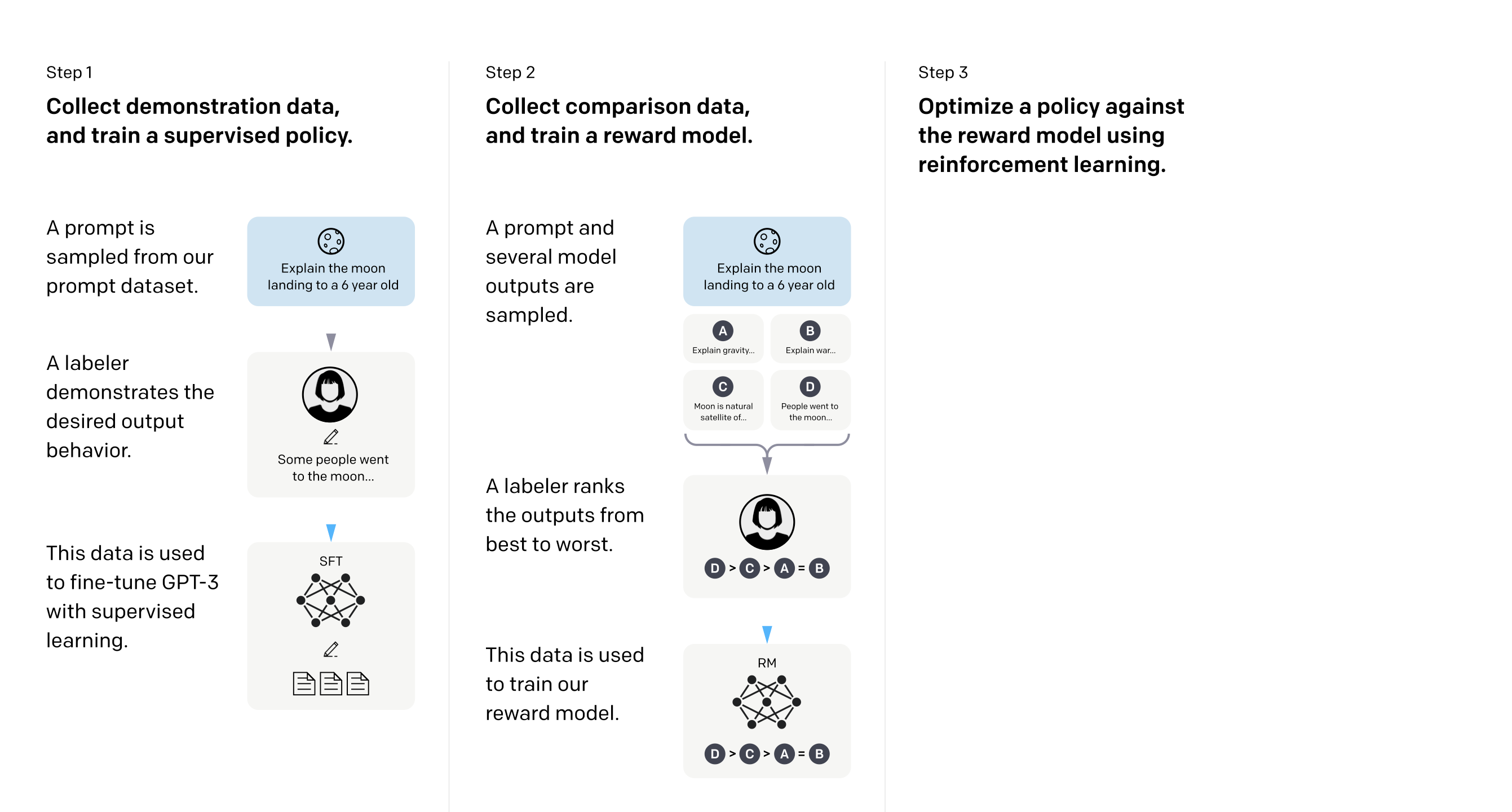
- Key point
- how to label SFT data
- how to label sorted data
- human come up with some promt and GPT playground
- helpfulness for traing and truthfulness and harmfulness for evaluation
- how to train RM
- Pairwith ranking loss
- K = 9 is effectiva not only for label cost but also for evaluation cost

- Pairwith ranking loss
- how to fine-tune mode with RM
- PPO-ptx
- maximize the reward for SFT model while keep the original ablity

- PPO-ptx
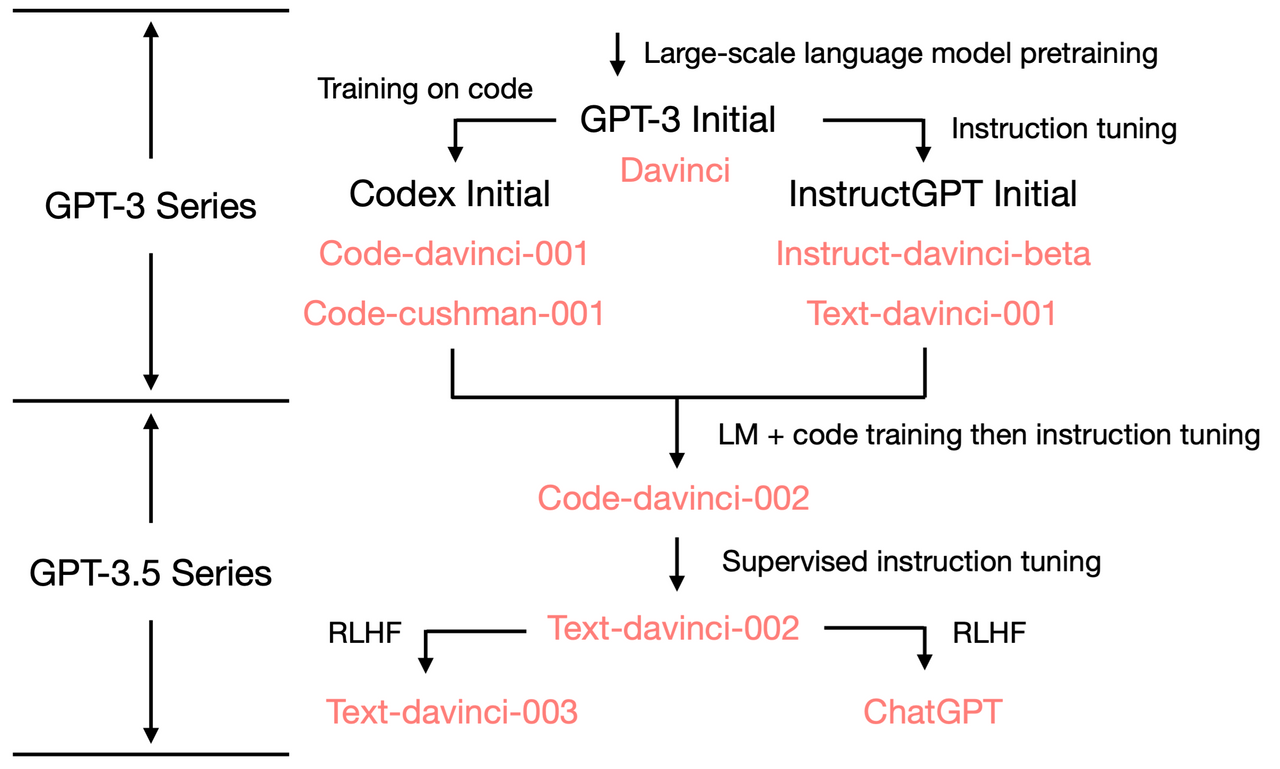
2. 大语言模型的微调
微调的综述:https://www.simform.com/blog/completeguide-finetuning-llm/
大模型微调技术 https://www.zhihu.com/question/599396505/answer/3141866148
微调Llama2的代码:Google colab + hugging face
https://www.youtube.com/watch?v=eeM6V5aPjhk&list=PLpdmBGJ6ELUKpTgL9RVR86cnPXjfscM5d&index=2
3. 微调模型的数据获取
爬虫的学习:https://github.com/Kr1s77/Python-crawler-tutorial-starts-from-zero/tree/master
4. 其他优秀的开源模型
Llama
Llama2是mata发布的免费可商用版本的开源大模型,一经发布就在圈内引起波然大轩。
- 论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
- 项目地址:https://github.com/facebookresearch/llama
但是Llama2的训练预料英文占比太高导致该模型在中文的表现能力上一般,为此,我寻找了其他在中文领域表现优秀的开源模型:
百川:
https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
中文版本的Llama2: