爬虫就是一系列操作的集合,用于在互联网上代替人工从事重复性的动作,本文从0基础开始介绍爬虫的基本原理,结合案例分析爬虫的实现流程。
预备知识
在学习爬虫之前,我们首先需要熟悉和网络相关的基本知识。我们从一个最基本的例子出发。
HTTP原理
URL
URL的全称为Universal Resource Locator,即统一资源定位符,也叫网页链接,它是互联网中资源的唯一标识符。
URL的组成如图所示:
scheme:协议。常用的协议有http、htps、fp等,另外schere也被常称作profocol,二者都代表协议的意思
usemame,password:用户名和密码。在某些情况下URL 需要提供用户名和密码才能访向,这时候可以把用户名和密码放在host前面,二者中间用分号隔开。例如https://admin:admin@ssr3.scrape.center。
hositname:主机地址。可以是域名或IP地址,比如https://www.baidu.com这个URL中的hostname就是www.baidu.com,这就是百度的二级域名。比如https://8.8.8.8这个URL中的hostname就是8.8.8.8,它是一个IP地址。
port:端口,http协议的默认端口是80,https协议的默认端口是443
path:路径。指的是网络资源在服务器中的指定地址,比如https:/github.com/favicon.ico中的path就是favicon.ico,指的是访问Gittfub根目录下的favicon.ico。
query:查询。用来查询某类资源,如果有多个查询,则用&隔开。query其实非常常见,比如https://www.baidu.com/s?wd=nba&ie=utf-8,其中的query部分就是wd=nba&ie=utr-8,这里指定了wd是nba.ie是urr8
fragment:片段。它是对资源描述的部分补充,可以理解为资源内部的书签。目前它有两个主要的应用,一个是用作单页面路由,比如现代前端框架Vue,React都可以借助它来做路由管理:另外一个是用作HTML铺点,用它可以控制一个页面打开时自动下滑滚动到某个特定的位置。

HTTP和HTTPS
在爬虫中,我们抓取的页面通常是基于http或https协议的,因此这里首先了解一下这两个协议的含义
HTTP的全称是HypertextTransterProtocol,中文名为超文本传输协议,其作用是把超文本数据从网络传揄到本地浏览器,能够保证高效而准确地传输超文本文档。
HTTPS的全称是HypertextTransferProtocoloverSecureSocketLayer,是以安全为目标的HTTP通道,简单讲就是HTTP的安全版,即在HTTP下加人SSL层。简称HTTPS
HTTP和HTTPS协议都展于计算机网络中的应用层协议,其下层是基于TCP协议实现的,TCP协议属于计算机网络中的传输层协议,包括建立连接时的三次握手和断开时的四次挥手等过程。
HTTP请求过程
浏览器是我们上网的入口,在我们的浏览器中输入一个网址(例如https://qinxuliang1997.github.io)后,到底发生了什么?
网页浏览的过程和书信通讯的过程很相似,我们需要提供通讯方的地址(网络地址)、书信的内容(浏览器会帮我们自动生成),随后浏览器会把这个地址连同书信的内容交给快递员(网络驱动器),然后这些信息就可以在网络高速路上驰骋,最终达到收信方后,对方会根据我们的书信内容选择需要回信或者是其他动作,回信的过程和上述类似,得到了回信后浏览器根据回信的内容将信息展示在网页上。
更加具体的描述过程见:
请求
请求,英文为Request,由客户端发往服务器,分为四部分内容:请求方法(RequestMethod)请求的网址(RequestURL)、请求头(RequestHeaders)、请求体(RequestBody)。
- 请求方法,用于标识请求客户端请求服务端的方式,常见的请求方法有两种:GET和POST。GET请求中的参数包含在URL里面,数据可以在URL中看到,而POST请求的URL不会包含这此数据,数据都是通过表单形式传输的,会包含在请求体中;GET请求提交的数据最多只有1024字节,POST方式则没有限制。
- 请求的网址,它可以唯一确定客户端想请求的资源
- 请求头,用来说明服务器要使用的附加信息,比较重要的信息有Host、Cookie、Referer、User-Agent、Content-Type等
- 请求体,一般承载的内容是POST请求中的表单数据,对于GET请求,请求体为空
响应
响应,即Response,由服务器返回给客户端,可以分为三部分:响应状态码(ResponseStatusCode)响应头(ResponseHeaders)和响应体(ResponseBody)
- 响应状态码,表示服务器的响应状态,如200代表服务器正常响应、404代表页面未找到、500代表服务器内部发生错误。
- 响应头,包含了服务器对请求的应答信息,如Content-Type、Server、Set-Cookie等。
- 响应体,这可以说是最关键的部分了,响应的正文数据都存在于响应体中,例如请求网页时,响应体就是网页的HTML代码:请求一张图片时,响应体就是图片的二进制数据。
Web网页基础
组成
网页可以分为三大部分: HTML、CSS和JavaScript。
HTML 定义了网页的内容和结构,CSS 描述了网页的样式,JavaScript 定义了网页的行为
HTML是一种用来描述网页的语言,它是网页基本的骨架和内容载体,网页通过不同类型的标签来表示不同类型的元素,如用img 标签表示图片、用 video 标签表示视频、用p 标签表示段落,这些标签之间的布局常由布局标签div 嵌套组合而成,各种标签通过不同的排列和嵌套形成最终的网页框架。
Css,全称叫作Cascading Style Sheets,即层叠样式表。它的作用是设置网页的样式,例如当前结构体的文字大小、颜色、间距、在页面中的位置等等;“层叠” 是指当HTML中引个几个样式文件,并且样式发生冲突时,浏览器能够按照层香顺序处理这些样式。
JavaScript 简称JS,是一种脚本语言,引入它的作用是为了给网页增加交互性和动态性,例如下载进度条,提示框等。
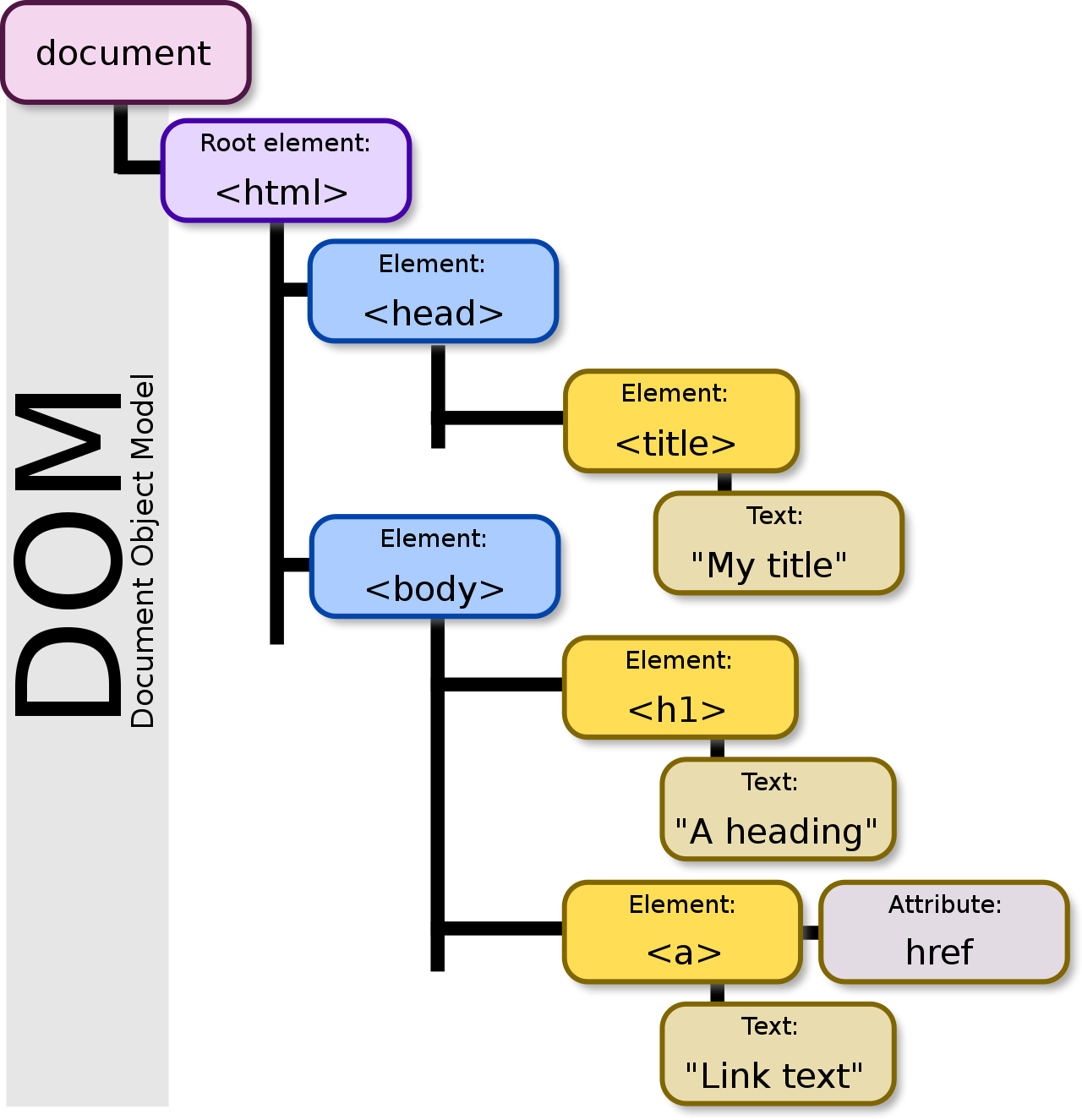
节点树
HTML的节点类型:https://www.w3schools.com/html/html_intro.asp
DOM树可视化:https://wow.techbrood.com/fiddle/29452
在HTML 中,所有标签定义的内容都是节点,这些节点构成一个HTML 节点树,也叫HTML DOM树,DOM 的最小组成单位叫做节点(node)。文档的树形结构(DOM 树),就是由各种不同类型的节点组成。每个节点可以看作是文档树的一片叶子。
节点的类型有七种。
Document:整个文档树的顶层节点DocumentType:doctype标签(比如<!DOCTYPE html>)Element:网页的各种HTML标签(比如<body>、<a>等)Attr:网页元素的属性(比如class="right")Text:标签之间或标签包含的文本Comment:注释DocumentFragment:文档的片段浏览器提供一个原生的节点对象
Node,上面这七种节点都继承了Node,因此具有一些共同的属性和方法。
选择器
css选择器会为不同的节点设置不同的样式规则,选择器则用于定位节点
最常用的三种方式分别是根据id.class、标签名选择。
- 节点的id为container,那么这个节点就可以表示为#container,其中以#开头代表选择id,其后跟的是id的名称。
- 如果想选择Class为wrapper的节点,则可以使用.wrapper,这里以.开头代表选择class,其后紧跟的是Class的名称。
- 跟据标签名,例如想选样二级标题,直接用h2即可
css选择器还支持嵌套选择,利用空格把各个选择器分隔开便可以代表嵌套关系,如Hcontainer .wrapper p代表先选择id为container的节点,然后选择其内部class为wrapper的节点,再进一步选择该节点内部的p节点。要是各个选择器之间不加空格,则代表并列关系,如divtcontainer.wrapperp.text代表先选择id为container的div节点,然后选择其内部Class为wrapper的节点,再进一步选择这个节点内部的Class为text的p节点。
爬虫概述
什么是爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
爬虫就是模拟浏览器的行为,越像越好,越像就越不容易被发现。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
爬虫的分类:
通用爬虫:通常指搜索引擎的爬虫聚焦爬虫:针对特定网站的爬虫
怎么实现
爬虫的流程包括四步:
- 获取url(列表)
- 请求url并获得响应
- 解析网页响应体获得内容
- 保存信息
获取网页
学习爬虫,其基本的操作便是模拟浏览器向服务器发出请求,python提供了很多功能强大的库帮助我们实现这个过程,其中最常见的就是requests,它的作用是模拟尽力模仿浏览器的一切行为,发送请求并获得服务器的响应。
最简单的例子:
1 | # !pip3 install request3 |
除了get方法外,request还支持post、put、delete、patch等方法。
在前面介绍url的构成是曾经提到url中可能会包含参数,例如:https://www.httpbin.org/get?name=germey&age=25。requests中可以使用如下的代码实现参数的传递:
1 | import requests |
在HTTP发起请求时,会有一个请求头Request Headers,这个头一般是浏览器自动生成的,没有这个头某些浏览器可能会检测到这不是一个正常的请求,因而导致异常。
requests中增加请求头的方式如下:
1 | import requests |
除了使用get方法外,post方法也是非常常见的,它的用法如下:
1 | import requests |
提取信息
在发送请求且无误后,就会得到服务器的响应信息,这些信息包括status_code,headers等等。
我们所关心的肯定是响应体,响应体是一个HTML文本,我们所感兴趣的内容有些是直接写在HTML中,还有些可能是经过JavaScript渲染出来的,还有些可能放回的是图片、音频、视频等。
- HTML(
r.text):HTML本质上就是文本信息,在文本中提取信息最直接的方法是使用正则表达式,或者使用BeautifulSoup等专门用于内容提取的库; - 图片、音频、视频(
r.content):这些文件本质上都是由二进制码组成的,可以将文件按照二进制的方式保存下来查看; - JavaScript渲染:现在越来越多的网页展现出的是JavaScript处理数据后的结果,实际和HTML中展示的不一样,这些数据可能来源自Ajax机制加载的,也可能是JavaScript和特定算法计算的等等,面对这些问题需要更加深入的探讨。
保存入库
保存信息的方式很多,简单的直接将其存在文件夹中,面对海量的数据也可能会使用数据库保存。
案例
有了上面的基本的知识,还是会发现在实际面临一个问题时候不知道从何下手,下面使用一个例子进行说明。
工具介绍
chrome开发者工具
https://zhuanlan.zhihu.com/p/47697445